
The Most Misunderstood Research Method In All The Land
At least twice a month, I stumble across someone asking for advice about conjoint analysis.
In most cases, they don’t know what conjoint analysis is actually for. But what’s worse is how often people replying to these questions don’t understand what conjoint analysis is for either!
I’ve replied to so many of these posts recently that I figured it was time to share a simple explanation publicly (partly so I can send them this link instead of a new reply every time!).
The reason I reply to these posts isn’t just because conjoint analysis is extremely expensive (conjoint tools cost up to $30,000/year and projects typically require hiring a conjoint expert on top of that). It’s because conjoint analysis is actually not well suited to the majority of user research scenarios — and can even leave you with useless data that doesn’t answer your core research objective.
This post covers five fundamental questions about conjoint analysis:

What is conjoint analysis? (Definition & Example)
Conjoint analysis is a survey format that measures which attributes are most important to customers when purchasing a product.
It presents a research participant with 3-6 product “profiles”, each made up of several “attributes”. The participant compares the profiles and picks the one they like most. Then a new set of profiles are loaded where the attribute categories are still the same but the attribute “levels” on each profile have been changed. After the participant has voted a couple of times, you can figure out which attributes and “levels” are having the most influence over their decisions.
Here’s a quick example — you’re hosting a barbecue this weekend and want to pick a combination of burger ingredients that will appeal to the most people possible. You decide to run a quick conjoint survey with three attributes (filling, sauce and bun) and four options (attribute options are known as ‘levels’) for each attribute.

The results of your conjoint analysis tell you which of these three attributes people care about most and which ‘levels’ within each attribute have the highest appeal (example results below).

Why do people so often misunderstand conjoint?
Most people mistakenly think conjoint analysis just means “measuring what’s most important to people”. In reality, conjoint only measures what’s most important to people when comparing products in a purchase scenario.
This creates a whole bunch of conditions for conjoint research — there can only be one person involved in the purchase decision, the range of products must be easily comparable, the customer must already know what kind of product they need, and the researcher has to know what attributes the customer uses to compare products.
Most of these conditions only apply in simple consumer goods scenarios, like deciding which laptop, shampoo, or barbecue burgers to buy. This makes sense — conjoint was popularized by the market research industry in the 1980s, whose customers were typically from consumer goods companies.
But buying software or B2B products isn’t like this at all. There’s generally more than one person involved in making the purchase decision. Customers often don’t know what product to buy to solve their problems. They don’t know how to compare products directly. B2B purchase decisions tend to be more about addressing needs/pains, availing of perceived benefits, and accomplishing key goals. These intangible attributes are impossible to measure in a conjoint survey. But they’re not entirely impossible to measure — you just need to be using the right research method…
What’s the right research approach to use?
Most times someone posts a question about conjoint analysis, what they’re actually thinking about is discrete-choice research — which is an umbrella term for a whole category of research methods that conjoint analysis belongs to.
Discrete-choice analysis (also known as “discrete-choice modeling” or “choice-based research”) is when you show people a set of options and infer what their preferences are based on the choices they make. It’s built on the principle that stated preferences are fundamentally unreliable — people often just don’t know what they want or are affected by other forces when articulating their preferences (like social status, perceived intelligence, idealistic self-image). Examples of stated preferences research methods include Likert Scale questions and NPS surveys.
Revealed preferences tend to be a better predictor of people’s true behavior. Conjoint analysis is a superb ‘revealed preference’ research method for understanding how people act in purchase scenarios. But for a whole other bunch of decisions, there are other discrete-choice methods that have superior advantages like context flexibility, lower cost, and reduced complexity.
In fact, you’ve probably heard about many of the other types of discrete-choice research, like ranked choice voting, points allocation / constant sum surveys, pairwise comparison, and maxdiff analysis:
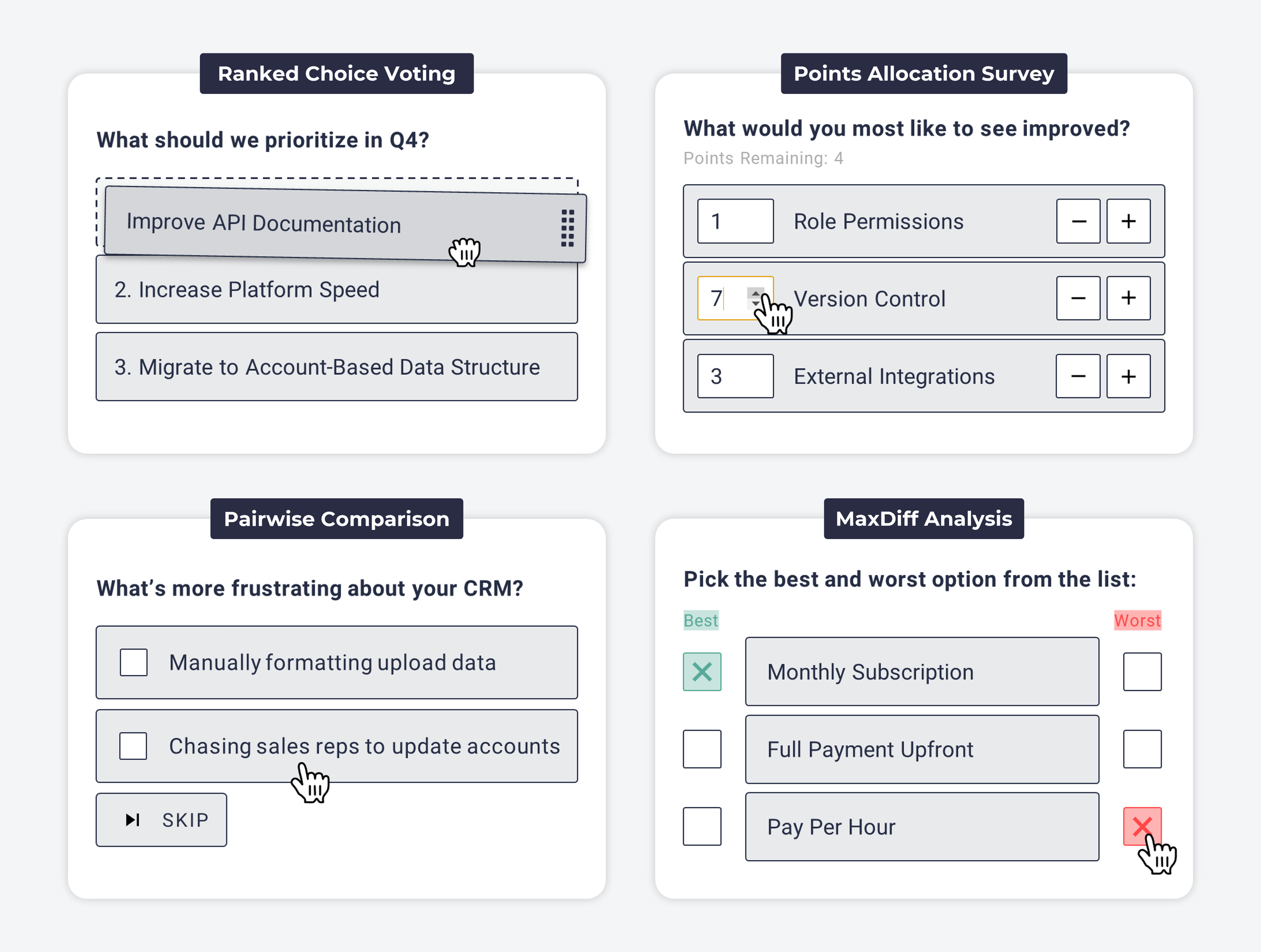
So when should I use conjoint analysis?
Conjoint analysis is most useful for research that involves purchase decisions, like calculating customers’ willingness to pay for existing features, modeling market share scenarios against competitor products, and informing optimal product bundling strategies (more on these examples here).
However, there’s one detail that rules conjoint analysis out even for research projects that initially look suitable. It all comes down to attributes.
If you want to use a conjoint survey to understand the relative importance of a list of options, you’ll have to split those options up into different “attribute” categories because each attribute can only have a maximum of ~7 options. Your results will tell you which attributes were most important and the relative importance of the options inside each attribute, but people often don’t realize that you can’t compare the importance of options across different attributes.

For many user research scenarios that focus on customers’ preferences — like product discovery, roadmap prioritization, and assumption testing — you don’t necessarily have distinct attribute categories (or even if you do, you’re often not sure what they are yet). But because you decided to use conjoint analysis, you’re forced to fit its format. That’s how you end up with data that doesn’t actually answer the primary research question you set out to address. That’s the biggest risk in assuming that conjoint analysis is the right method for your research.
I wrote a longer post that goes into much deeper detail on this and includes 10 examples of user research projects that aren’t suited to conjoint analysis, so I recommend you continue there if this topic is of interest.
Where can I learn more about conjoint analysis?
I spent the past fortnight writing 10,000+ words about conjoint analysis, which I’ve turned into a handful of separate articles.
To start, here’s a breakdown of 8 research alternatives to conjoint analysis that explains the various discrete-choice methods you can use to measure relative importance via revealed preferences.
If you’re considering conjoint analysis for your research, see if your project meets these 5 criteria for assessing whether conjoint analysis suits your research scenario. If it does, here’s a breakdown of the 10 most popular conjoint analysis tools (including whether they’ve got a free plan and how much their paid plan costs — spoiler: $3,000 to $30,000 per year excluding support services).
To go deeper on the technical side of conjoint analysis, see my explanation of the 13 different types of conjoint analysis (with picture examples) or take a look at this advanced breakdown of how to calculate conjoint results data in 8 steps.
Alternatively, click any of the thumbnails below to read the articles:





About The Author:
Daniel Kyne is the Co-Founder of OpinionX, a free research tool for stack ranking people’s priorities — used by thousands of product teams to better understand what matters most to their customers. OpinionX has a bunch of free research methods for ranking people’s preferences — including Conjoint-style ranking methods like Pairwise Comparison and Constant Sum. Try it now!